這篇文章講資料的視覺化分析。
繪圖套件 ggplot2
ggplot2是一套龐大且強大的繪圖系統。其概念是使用結構性語法,先指定資料,再指定變數,然後指定幾何元素,最後處理標題與標註資料以及背景的主題樣式。這個處理模式幾乎等同於在Excel等試算表類統計軟體中的處理模式。
ggplot2的繪圖元件
- 資料(data):繪圖的資料來源,一般會先使用
ggplot()來輸入資料。 - 幾何元件(geometry):繪圖的類型,例如柱狀圖、散佈圖、盒鬚圖等。
- 座標系統(coordinate system):繪圖的座標系統,預設是
coord_cartesian(),即笛卡兒座標系。
ggplot2的語法結構
ggplot2的語法結構一般遵循下面:
1 | ggplot(data = $data) + |
以ggplot2繪製的徒刑必須要包含至少兩個必要的元件——ggplot(data)和geom_funtion(mapping)。
ggplot2繪圖入門示例
雙變數
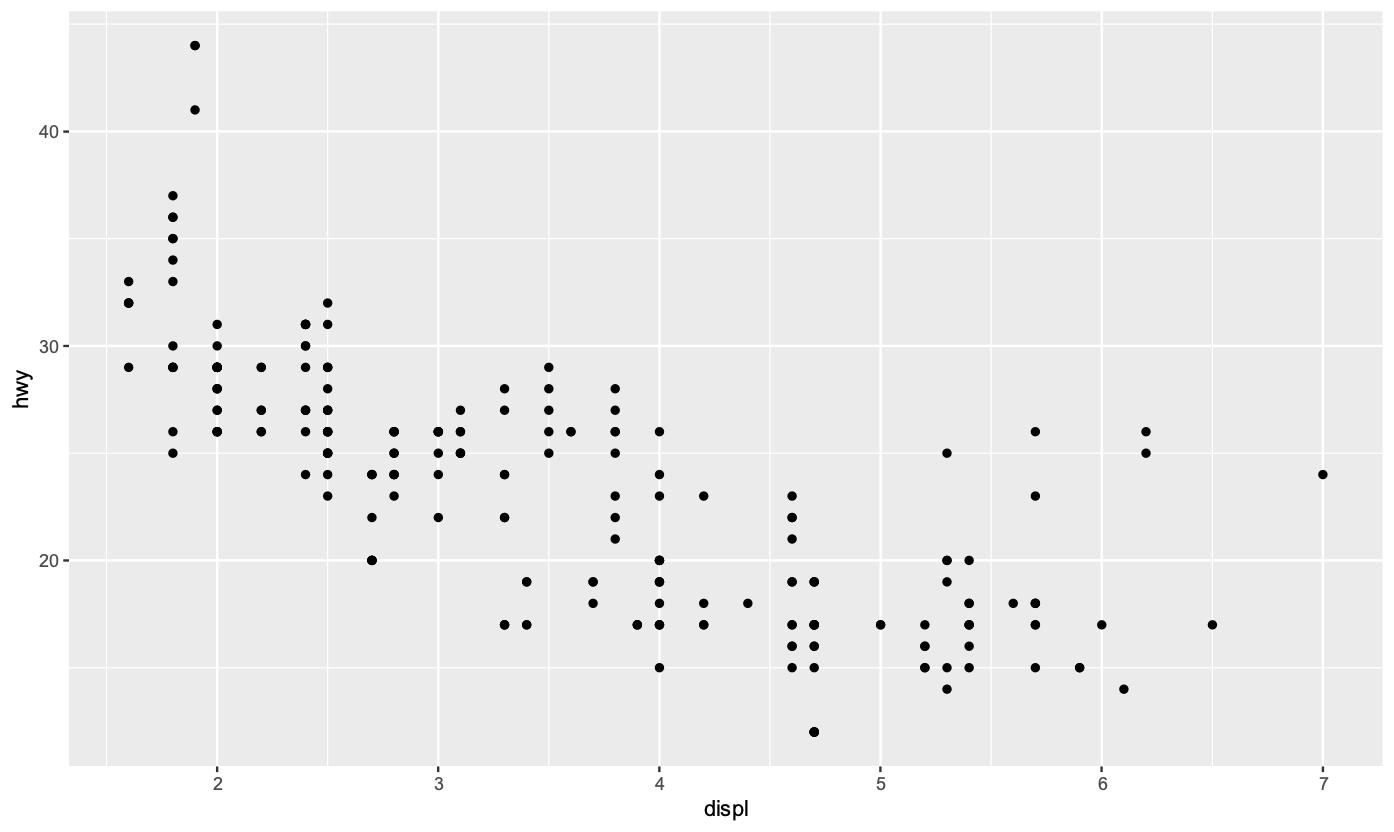
我們使用R Lang內建的資料集mpg來進行練習。mpg是1999年到2008年之間38個流行車型的燃油經濟資料。
我們假設要繪製一個散佈圖,x變數和y變數分別是displ(發動機排氣量)和hwy(高速油耗)。那麼我們的程式碼如下:
1 | library(ggplot2) # 載入ggplot2套件 |
繪製結果如下:
三個及以上變數
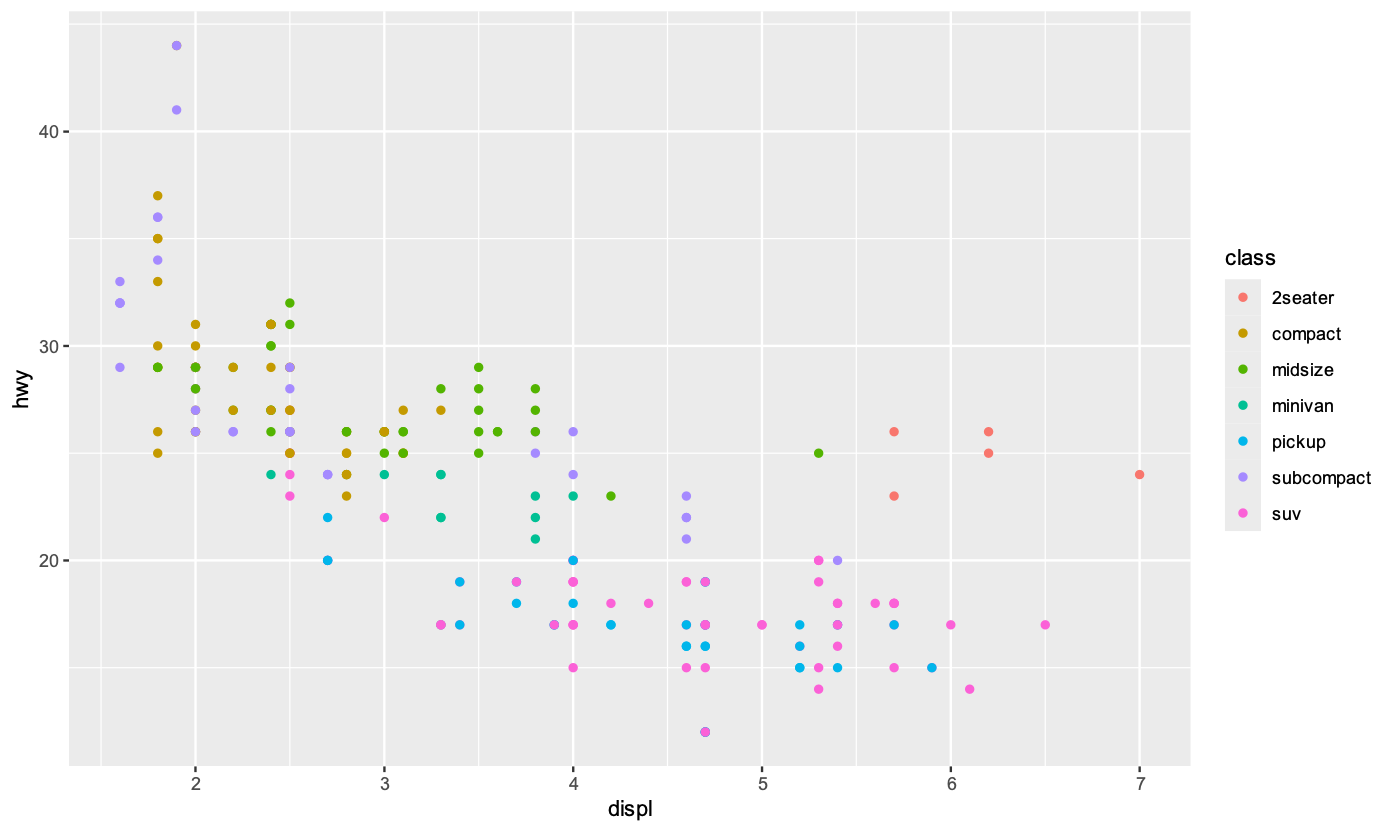
如果我們需要繪製三個以上的變數,我們可以使用顏色來區分:
1 | library(ggplot2) |
繪圖結果如下:
套用多個幾何元件圖層
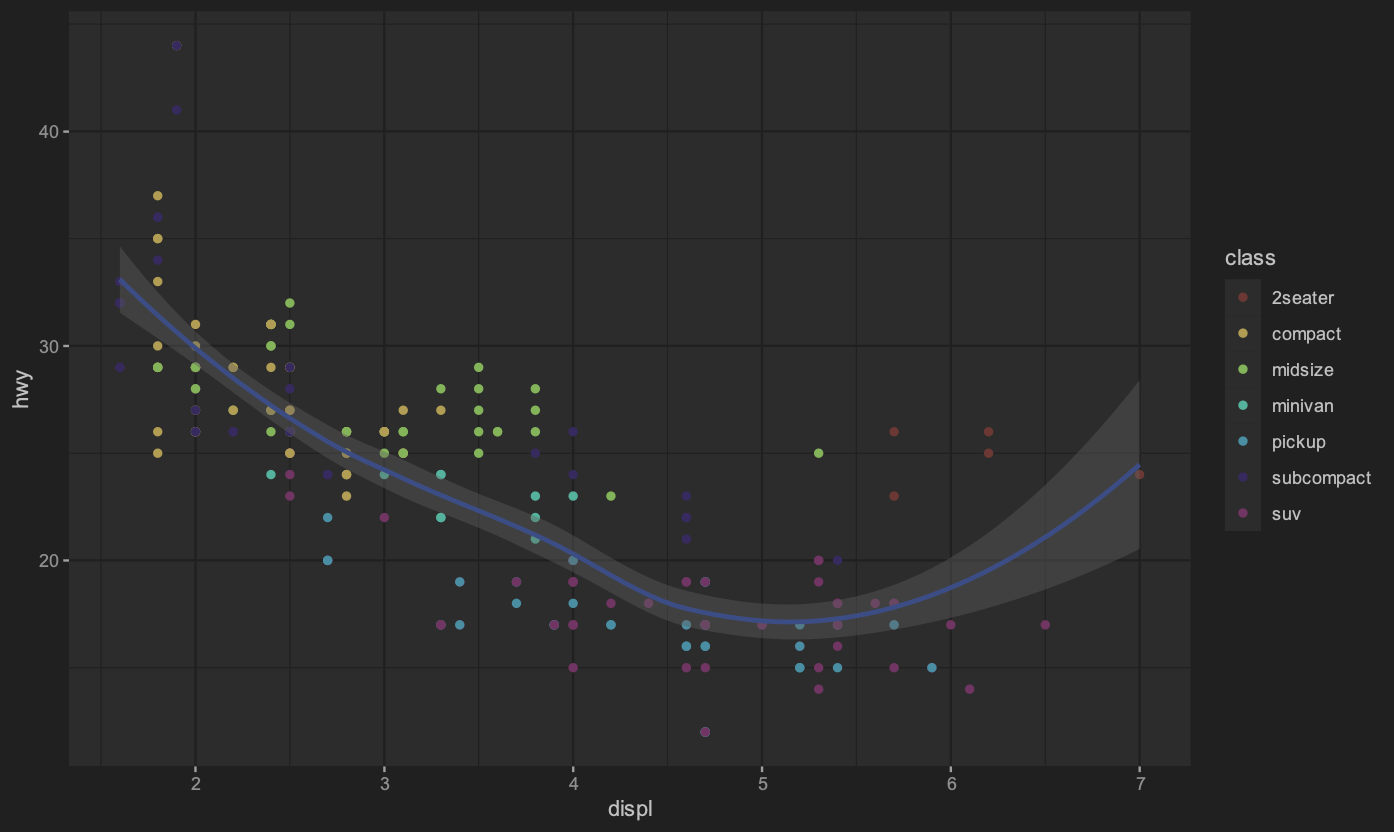
我們可以將多個繪圖元件作為不同的圖層疊加在一起:
1 | ggplot(data = mpg) + geom_point(mapping = aes(x = displ, y = hwy, color = class)) + geom_smooth(mapping = aes(x = displ, y = hwy)) |
繪圖如下:
回歸模型的套用
我們也能在 ggplot2 中套用不同的統計模式,像是迴歸模型(regression models)。假設我們想求得發動機排氣量和高速油耗之間的關聯性,可以使用簡單線性迴歸,類似在上面使用 geom_smooth()的方式,只需要加上 method = “lm” 即可(lm 代表 linear regression),繪圖的時候 ggplot2 也會自動預設加上信賴區間。
1 | ggplot(data = mpg) + geom_point(mapping = aes(x = displ, y = hwy, color = class)) + geom_smooth(mapping = aes(x = displ, y = hwy), method = "lm") |
geom_smooth()預設支援常用的幾種回歸模式。例如線性回歸(lm)、廣義線型模型(glm)、廣義加成模型(gam),還可以自定義模型。例子如下,使用
1 | ggplot(data = mpg) + geom_point(mapping = aes(x = displ, y = hwy, color = class)) + |
繪圖如下: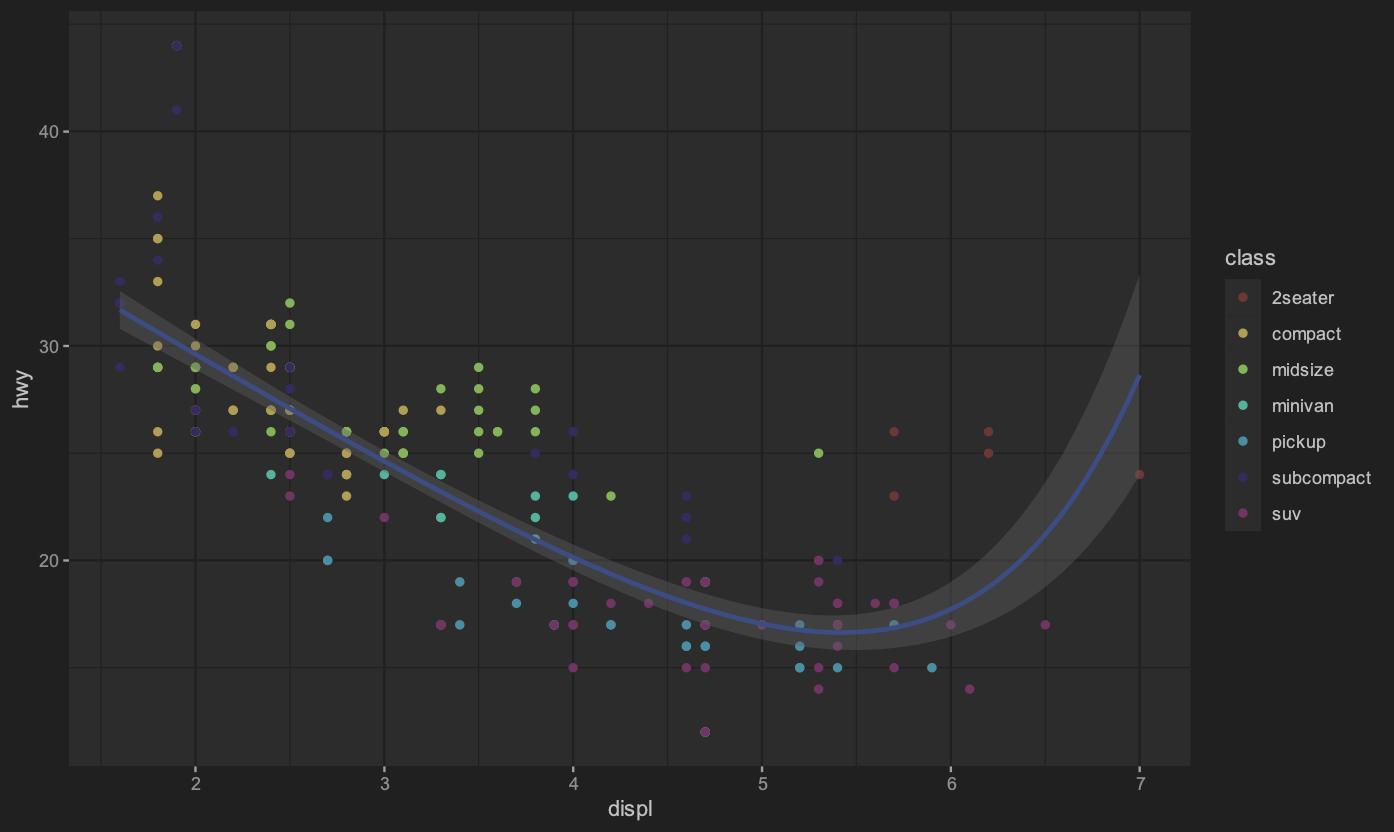
套用不同的主題
要套用不同的主題,調用不同的主題函式即可。
1 | ggplot(data = mpg) + |
aes或geom_$function引數
- x:設定x變數。
- y:設定y變數。
- alpha:透明度。數值為0~1。學習前端的讀者應該會很好理解。
- color:前景顏色,可以使用顏色的英文或者16進位碼。
- fill:背景顏色。
- linestyle:線條的類型,0~6代碼分別為:空白(blank)、實線(solid)、虛線(dashed)、點線(dotted)、點虛線(dotdash)、長虛線(longdash)、雙虛線(twodash)
- size:線條粗細
- shape:圖形類別,0~16
- weight:權重
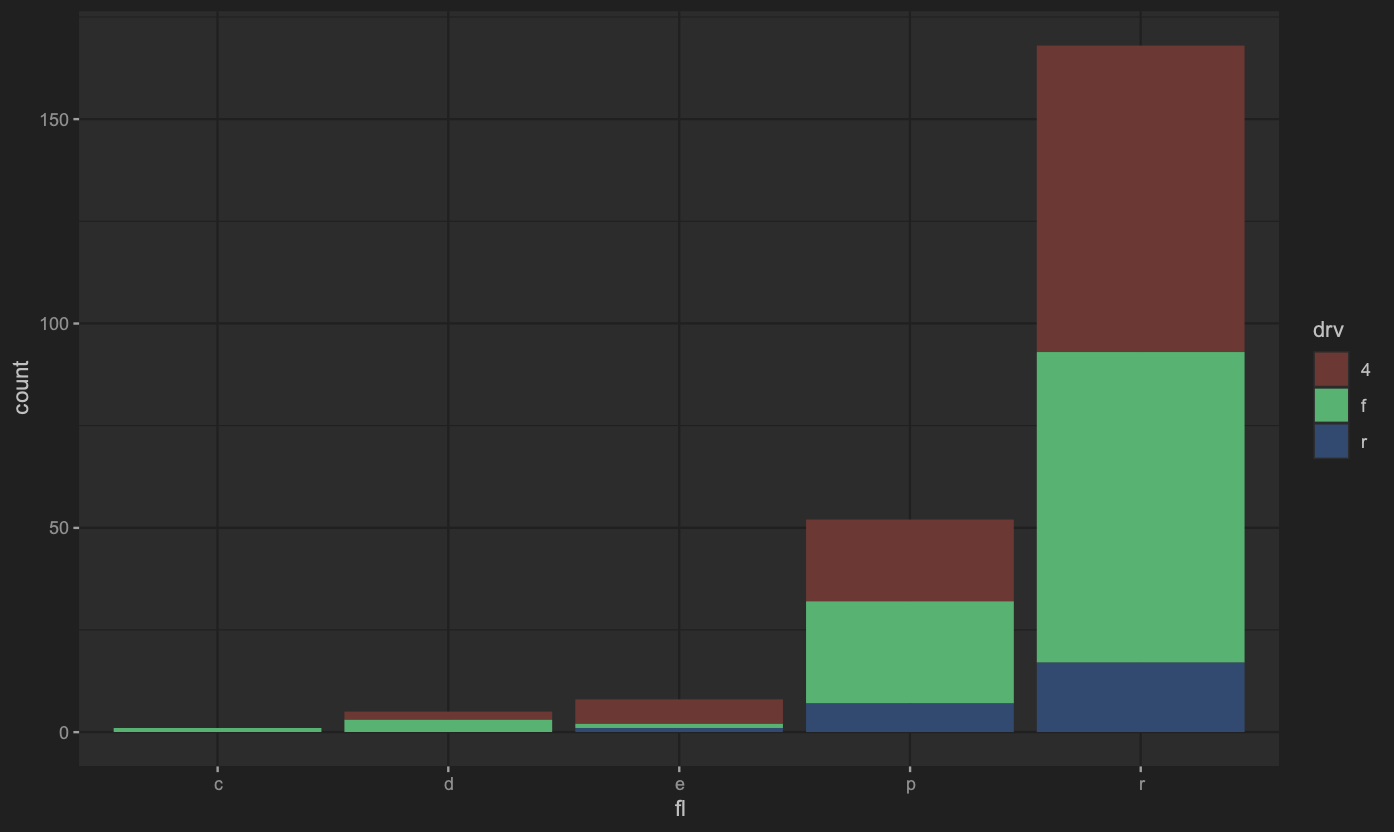
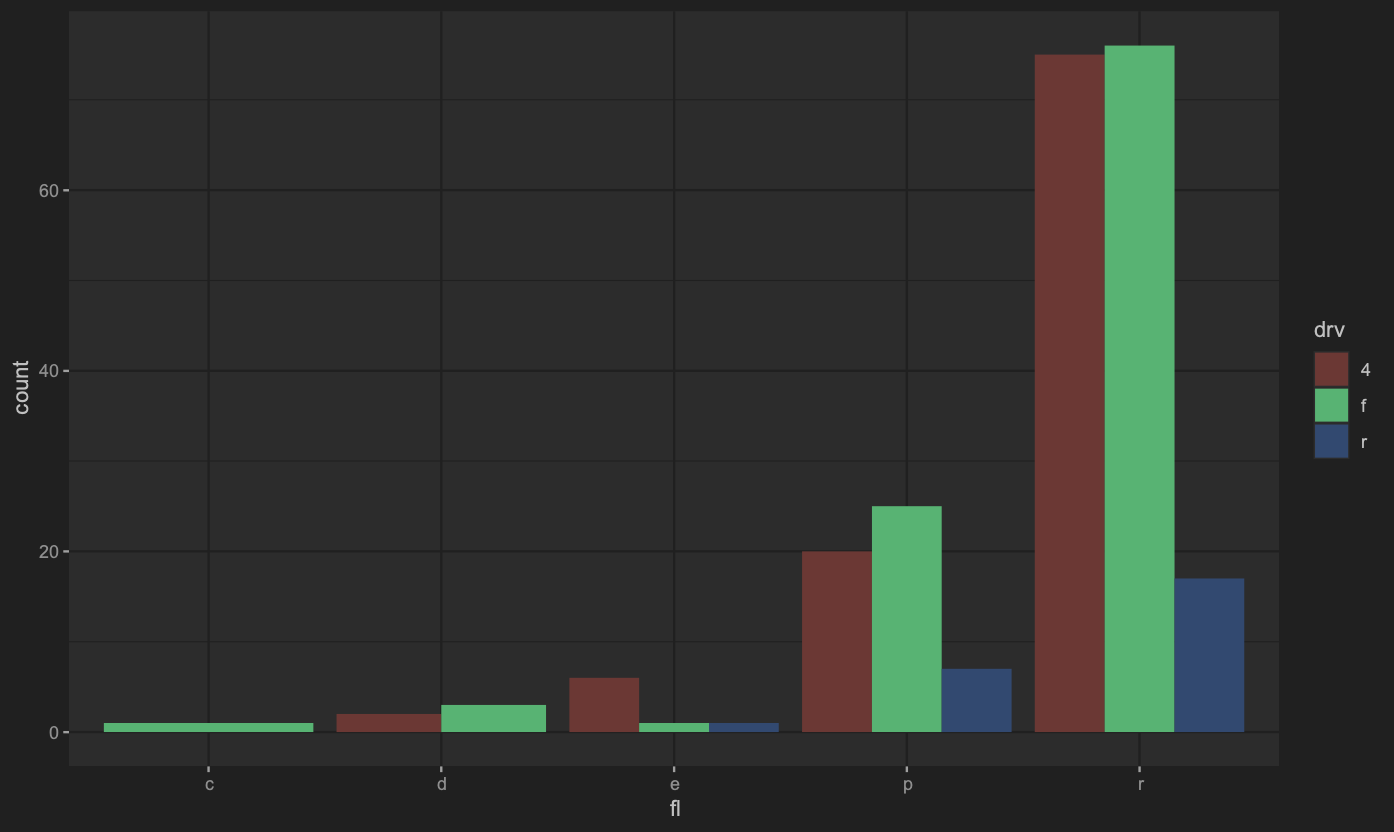
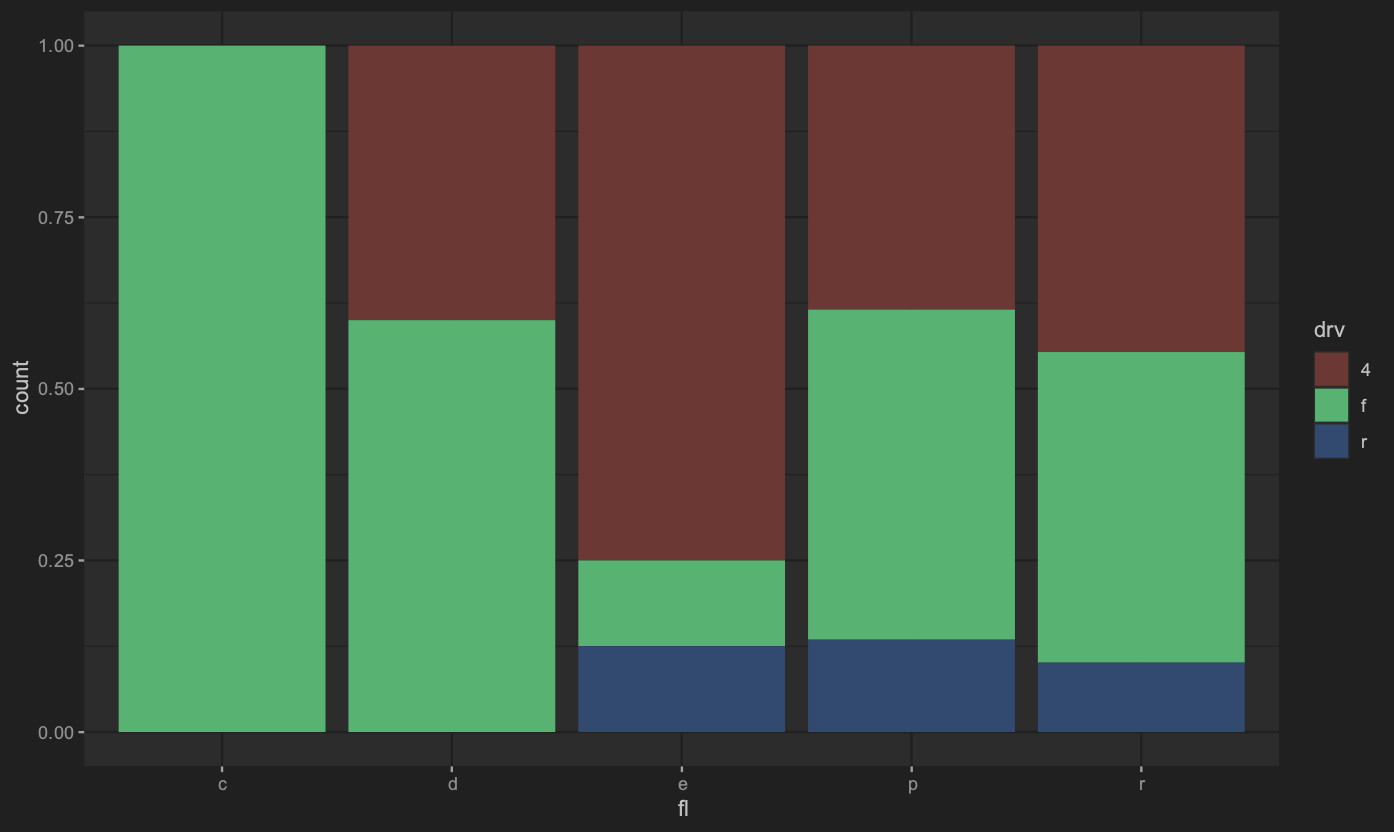
排列位置調整
排列方式會有分散排列(dodge)、填滿在某個元件之中(fill)、堆疊(stack)、分散點排列(jitter)、推移(nudge)等。
1 | ## 預設為stack |
1 | ## 修改position為dodge |
1 | ## 修改position為fill |
加入誤差棒
有時候在繪圖的時候,我們會在圖上面加註誤差棒,以了解數據的誤差範圍。若誤差棒的長度愈長,代表其誤差愈大。誤差棒的長度一般是標準差(standard deviation)或標準誤(standard error)。ggplot2 可使用geom_errorbar(), geom_linerange(), geom_pointrange() 或 geom_crossbar() 等。
各種統計用圖的資料類型一覽
| 變數數目 | 變數類型 | 圖形類型 | ggplot2幾何元件 | 解釋與適用資料 |
|---|---|---|---|---|
| 1 | 連續 | 直方圖 | geom_histogram() | 觀察數據分佈的大致情況,應用在連續性的數值上 |
| 1 | 連續 | 多邊圖 | geom_freqpoly() | 觀察數據分佈的大致情況,和直方圖很類似,只不過繪製成折線,適合疊加多個變數後比較 |
| 1 | 連續 | 點圖 | geom_dotplot() | 觀察數據分佈的大致情況,和直方圖很類似,只不過以點來呈現 |
| 1 | 連續 | 核密度估計圖 | geom_density() | 觀察數據分佈的大致情況,將直方圖轉換成折線方式呈現,使用機率密度的函數來計算繪製 |
| 1 | 連續 | 分位圖 | geom_qq, geom_qq_line() | 適用於監測數據分佈是否常態 |
| 1 | 連續 | 盒鬚圖 | geom_boxplot() | 了解資料的分散狀況,可從盒鬚圖中觀察出中位數、四分位數和最大最小值 |
| 1 | 離散 | 柱狀圖/長條圖 | geom_bar() | 比較一個變數小規模的資料分析,適用於離散型資料 |
| 2 | 連續 | 散佈圖 | geom_point | 將兩個變數以點呈現,可協助瞭解兩者之間有無關聯,可搭配geom_smooth() |
| 2 | 連續 | 面積圖 | geom_area() | |
| 2 | 連續 | 折線圖 | geom_line() | 連續性的資料,把所有的點用線段連結起來,觀察x軸的變數序列上y的變化情形 |
| 2 | 連續 | 鬚軸圖 | geom_rug() | 在兩個軸上精簡表示兩個連續變數的圖,通常適合小資料集 |
| 2 | 連續 | 平滑曲線圖 | geom_smooth() | 把所有的資料平滑化後繪製,一般協助觀察並找出資料的特徵 |
| 2 | 連續 + 離散 | 柱狀圖 | geom_col() | |
| 2 | 連續 + 離散 | 盒鬚圖 | geom_boxplot() | 了解資料的分散狀況,可從盒鬚圖中觀察出中位數、四分位數和最大最小值 |
| 2 | 連續 + 離散 | 提琴圖 | geom_violin() | 同時顯示數據分布和其機率密度,結合盒鬚圖和核密度估計圖 |
| 3 | 連續 | 等高線圖 | geom_contour(), geom_contour_fill() | GIS地形高度資料 |
| 3 | 連續 | 影像網格 | geom_raster() | 地圖資料,和 geom_tile() 與 geom_rect() 相同,當所有的圖磚大小相同時,繪製地圖的效率較 geom_tile() 或 geom_rect() 來得高 |
| 3 | 連續 | 圖磚 | geom_tile(), geom_rect() | 繪製矩形範圍,定義邊界(數值範圍四個角落,geom_rect)或圖磚大小(geom_tile)。通常使用作為地圖上或熱點圖的資料呈現 |